

2020-11-05 | Martin Weißbach | 5 min read
Die Geschichte eines Performance-Einbruchs feat. Prometheus
Prolog
Die Scandio betreut für einen renommierten internationalen Hausgerätehersteller im SmartHome Umfeld die Entwicklung eines logisch zentralen Gateways, welches den Austausch von Informationen zwischen Hausgeräten und Backend Services ermöglicht, um zum Beispiel ein vorhandenes Hausgerät via App fernsteuern zu können.
Dabei sind mehrere Tausend Hausgeräte gleichzeitig über eine permanente TCP Verbindung mit dem Gateway verbunden, um den bidirektionalen Nachrichtenfluss zu ermöglichen.
Da das Gateway höchsten Anforderungen an Performanz und Verfügbarkeit genügen muss, werden mithilfe regelmäßiger Lasttests Performanz Metriken erstellt und mit früheren Werten älterer Entwicklungsstände verglichen, um Performance-Regressions frühzeitig zu erkennen. Bei einem dieser Tests wurde ersichtlich, dass einer der Services, aus denen das Gateway besteht, die CPU seines Hosts um den Faktor 5 stärker belastete als Vorgängerversionen, wenn kontinuierlich neue Hausgeräte (mocks) verbunden wurden. Da dieser Service für das Management der TCP Verbindungen zu den Hausgeräten verantwortlich und essentiell für den Nachrichtenaustausch ist, hat eine dermaßen höhere Belastung der CPU unmittelbar zur Folge, dass weniger Hausgeräte pro Host-Instanz verbunden werden können.
CPU Profile von Go-Apps
Einen Performance-Verlust in dieser Größenordnung können wir natürlich nicht einfach so stehen lassen und so begann die Ursachenforschung. Wir konnten sehr schnell die beiden konkreten Software-Versionen des Websocket-Manager (WSM) getauften Service, der die langlebigen TCP Verbindungen zu den Hausgeräten hält, identifizieren, die es zu untersuchen lohnt. Also die letzte Version mit bekannter geringer CPU-Belastung und die erste Version, die sich durch die hohe CPU-Last auszeichnet. Bei dem ersten Test wurden mehrere Versionen übersprungen. An dieser Stelle sei kurz gesagt, dass bei uns eine Version nicht gleichzusetzen ist mit einem Product-Increment. Durch die Verwendung von Semantic-Release und entsprechenden Build-Stages wird die Version von Services, die von uns entwickelt werden, wesentlich feingranularer inkrementiert.
Das Changeset zwischen diesen beiden Software-Versionen war groß und umfasste auch einige Refactoring Commits. Nach erster oberflächlicher Suche durch den Quellcode nach dem Offensichtlichen war uns schleierhaft, welche Änderung so katastrophale Auswirkungen haben sollte. Als nächsten Schritt haben wir unserem WSM einen Debug-Endpunkt [1] spendiert, der sich konfigurierbar aktivieren lässt, und auf unseren Notebooks aus Tests gestartet. Mit diesem Debug-Endpunkt lassen sich unter anderem CPU Profile erzeugen und abrufen, die dann offline ausgewertet werden können. Wir hatten natürlich gehofft, schon mit kleinen Hausgerätezahlen einen Ausreißer zu entdecken. Unsere Hoffnungen wurden leider enttäuscht. Die beiden Software-Versionen, die mit dem besagten Debug-Endpunkt modifiziert wurden, mussten also auf die Lasttest-Stages deployed werden, um von dort aus die CPU Profile während eines laufenden Lasttests zu generieren.
Die Ergebnisse waren einigermaßen erschütternd, denn damit hatte keiner gerechnet:
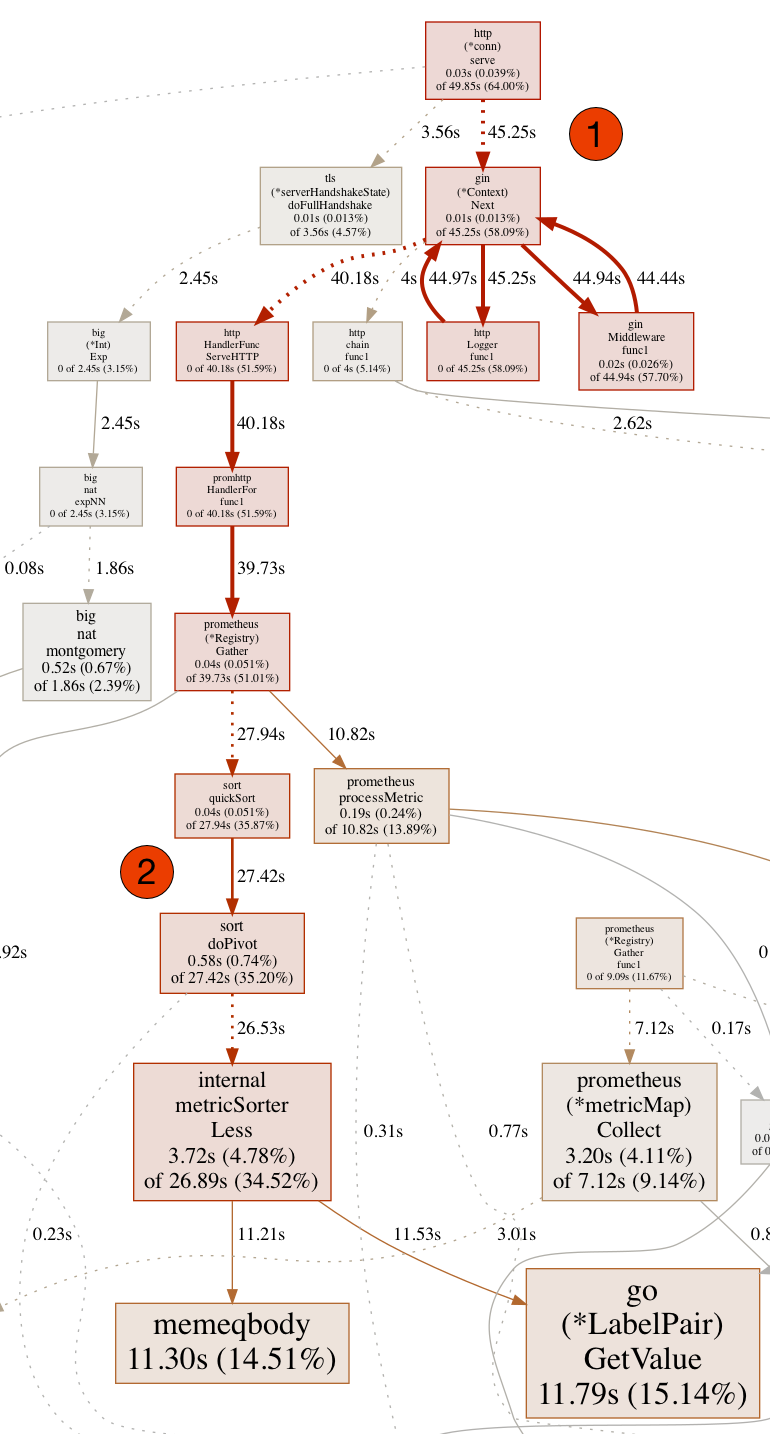
Wie in diesem Ausschnitt des kompletten CPU Profils zu erkennen ist, verursacht der HTTP Endpunkt (1) und die nachgelagerte Middleware eine hohe CPU-Last. Wir haben in unseren Kubernetes Clustern Prometheus [4] via Helm [7] Chart [5,6] aufgesetzt, um diverse Metriken sowohl unseres Clusters, als auch unserer eigenen Services verfügbar zu machen. Wie nun aus dem Trace ersichtlich ist, benötigt die Prometheus Library bzw. dessen Instanz zur Laufzeit sehr viel Zeit zum Sortieren der Metriken und Einfügen von Updates (2) während der Abarbeitung eines HTTP-Requests.
Label an Prometheus’ Metriken sind das Problem
Das Problem hat also mit Prometheus und Metriken, die am WSM generiert werden, zu tun. An diesem Punkt haben wir aber alle schwarze Katzen von links nach rechts an der Tür vorbeigehen sehen. Ein ähnlich gelagertes Problem hatten wir schon bei unserer alten und mittlerweile abgelösten Implementierung des Reverse Proxy. Das Problem war damals, dass wir die URLs inklusive vollständiger und nicht hinreichend genau normalisierter Pfade als Label an die Metriken fügten, was Prometheus nur bis zu einem bestimmten Grad toleriert. Was danach passiert, kann man beispielhaft an dem CPU Profil oben erkennen.
Die Suche im Changeset ging in eine neue Runde und tatsächlich hatten wir Metriken für Inbound-Requests am WSM bisher nur von dessen internen REST-Endpunkt genommen, jetzt aber auch von den öffentlichen Endpunkten für Websocket-Verbindungen. Die Umstellung geschah im Rahmen des Einsatzes einer dedizierten Middleware [2] für unsere Gin-Server [3] am WSM. Diese Middleware fügt den Pfad auf ziemlich naive Weise als Label hinzu: nämlich komplett, inklusive Query-Parametern. Wenn ein Hausgerät eine Verbindung zu Heimdall öffnet, wird typischerweise folgende URL inkl. Pfad aufgerufen: wss://<domain>.<name>.com/websocket?appliance=<id>.
Der Query-Parameter ist das Problem, denn die Prometheus Middleware baut das Label “url” mit folgendem Wert: /websocket?appliance=<id>.
Daraus folgt unmittelbar, dass jedes einzelne Hausgerät eine eigene Instanz der Metrik bekommt für beispielsweise die Anzahl der Aufrufe des Endpunkts, aber auch für die Status-Codes, die auf dem Endpunkt übertragen werden. Das entspricht schlussendlich genau der durch das CPU Profil offenbarten Beobachtung: Prometheus kann clientseitig neue Metrikinstanzen nicht mehr mit vertretbarem Aufwand in die Menge der bereits bekannten Instanzen einfügen bzw. innerhalb derer suchen. Was sind Labels?
An dieser Stelle muss festgehalten werden, dass Metriken über mehr als ein Label verfügen können. Ein Label ist der Key, zu dem es einen Wert gibt. Die Metrik selbst hat wieder einen Wert. Der Wert der Metrik selbst wird nur erhöht, wenn alle Werte aller Label gleich sind. Jede Permutation der Label-Werte ist effektiv eine neue Instanz dieser Metrik. Ein Beispiel:

Die in der Prometheus Client Bibliothek definierte Metrik heißt "http_request_counter" und summiert die Anzahl der Aufrufe auf und fügt noch zusätzliche Informationen, wie den konkret aufgerufenen Pfad oder den ausgelieferten Status-Code, an. Jeder neue Pfad, beziehungsweise jeder neue Status-Code, der noch nicht als Wert vorhanden ist, resultiert in einer neuen Instanz der Metrik zur Laufzeit, die entsprechend eigenständig verwaltet wird.
Unsere Lösungsidee
Glücklicherweise lässt sich mit diesem Befund arbeiten und ermöglicht eine schnelle und tragfähige Lösung. Die eingesetzte Prometheus Middleware [2] erlaubt die Implementierung einer Hook-Funktion (ähnlich dem Template Method Design Pattern [8], aber ob der Klassenlosigkeit von Go nicht ganz vergleichbar), um den Wert des “url” Labels anhand des Inbound-Request den eigenen Bedürfnissen anzupassen. Dieser Hook ist explizit für die Normalisierung von Pfaden gedacht, adressiert also bereits exakt das Problem, welches wir soeben identifiziert haben. Unsere Implementierung des Hooks folgt dann eher dem Prinzip Brechstange: Wir setzen den Wert immer auf “” (Leerstring). Warum ist das praktikabel? Die verwendete Prometheus Middleware [2] fügt ebenfalls den Namen des Handlers als Label an, der am Ende der Middleware den Request final bearbeitet. Dieser Handler kommt von uns, das heißt, wir kennen den Namen und können damit unmittelbar Metriken zu konkreten Endpunkten zuordnen.
Takeaways
- Ab 150.000 unterschiedlichen Labels ist der Prometheus Client-Library Port für Go nicht mehr funktionsfähig.
- Benutze keine Labels, deren Menge möglicher Werte du nicht kennst oder abschätzen kannst, oder diese Menge keine feste Größe hat.
- Wenn du für REST-Endpunkte Middleware-Lösungen für die Generierung von Standard-Metriken benutzen möchtest, schau dir an, ob und wie Pfade und URLs als Label gesetzt werden.
- Variante Pfad-Elemente, die beispielsweise Resourcen-IDs kodieren, führen ebenso über kurz oder lang ins Verderben, wenn sie es als Label-Wert an die Metrik schaffen.
Referenzen
[1] https://github.com/gin-contrib/pprof
[2] https://github.com/zsais/go-gin-prometheus
[3] https://github.com/gin-gonic/gin
[4] https://prometheus.io/docs/introduction/overview/
[5] https://github.com/helm/charts/tree/master/stable/prometheus
[6] https://artifacthub.io/packages/helm/prometheus-community/prometheus
[7] https://helm.sh
[8] Gamma, Erich, et al. “Design patterns: Abstraction and reuse of object-oriented design.” European Conference on Object-Oriented Programming. Springer, Berlin, Heidelberg, 1993.
Scandiolife auf Instagram.
Connecte dich auf LinkedIn mit uns.
Hier zwitschert die Scandio auf Twitter.

