

2021-07-08 | Verena Stiegler | 4 min read
High Availability in der Cloud - Was heißt das und brauche ich das wirklich?

High Availability - Brauch ich das?
High Availability ist und bleibt eines der zentralen Themen, wenn es um das Hosting und die Betreuung von Anwendungen geht. Besonders die zunehmende Verlagerung betriebskritischer Systeme in die Cloud macht Hochverfügbarkeit zu einem immer wichtigeren Kriterium.
Doch was genau steckt hinter “High Availability”? Sogenannte hochverfügbare Systeme arbeiten auch dann weiter, wenn kritische Komponenten ausfallen. Sie sind besonders belastbar, d. h. sie sind in der Lage, Ausfälle einfach zu bewältigen, ohne dass es zu Dienstunterbrechungen oder Datenverlusten kommt. Hochverfügbarkeit bezieht sich auf die Fähigkeit, ungeplante Ausfälle zu vermeiden, indem der Single-Point-of-Failure (SPOF) eliminiert wird. Ein Single Point of Failure ist jede Komponente des Systems, deren Ausfall zum Ausfall des Gesamtsystems führen würde.
Die Hochverfügbarkeit wird in der Regel als Prozentsatz der Betriebszeit (oder auch “Uptime”) gemessen. Die Anzahl der “Neunen” wird üblicherweise verwendet, um den Grad der Hochverfügbarkeit anzugeben. Vier “Neunen” stehen beispielsweise für ein System, das 99,99 % der Zeit verfügbar ist, was rein rechnerisch bedeutet, dass es während eines ganzen Jahres nur maximal 52,6 Minuten lang nicht betriebsbereit ist.
Ist bei einem Ausfall des Systems schnell ein großer finanzieller Verlust oder sonstiger Schaden zu befürchten, ist die Entscheidung für ein hochverfügbares System klar anzuraten.
Lassen Sie uns noch einmal rechnen:
| Verfügbarkeit | Mögliche Downtime / Jahr |
|---|---|
| 90% | 36,5 Tage |
| 99% | 3,65 Tage |
| 99,9% | 8,67 Stunden |
| 99,99% | 52,56 Minuten |
| 99,999% | 5,26 Minuten |
Insbesondere bei der Implementierung neuer Produkte stellt die Auswahl des Produktanbieters und des Anwendungsdesigns im Bezug auf Hochverfügbarkeit die größte Herausforderung dar. Aber gerade kleine Unternehmen legen auf solche Aspekte sowie einen umfänglichen 24/7 Systemsupport keinen großen Wert. Dies kann letzten Endes dazu führen, dass die System-Architektur nicht mit den Hochverfügbarkeitslösungen des Unternehmens kompatibel ist, was erneut hohe Kosten verursacht.
Wie eine solche hochverfügbare Cloud-Umgebung aussehen kann und worauf man vor der Implementierung achten sollte, zeigen wir Ihnen am Beispiel unseres Partners AWS.
High Availability in der AWS Cloud
Diese Elemente helfen Ihnen bei der Implementierung hochverfügbarer Systeme:
Redundanz — Stellen Sie sicher, dass kritische Systemkomponenten über eine weitere identische Komponente mit den gleichen Daten verfügen, die im Falle eines Ausfalls übernehmen kann.
Monitoring — Identifizieren Sie Probleme im System, die den Betrieb stören oder beeinträchtigen können.
Failover — die Fähigkeit, bei Ausfall, drohendem Ausfall, verminderter Leistung oder Funktionalität von einer aktiven Systemkomponente auf eine redundante Komponente umzuschalten.
Failback — die Fähigkeit, von einer redundanten Komponente auf die primäre aktive Komponente zurückzuschalten, wenn diese sich von einem Ausfall erholt hat.
Availability Zones
Um eine möglichst hohe Verfügbarkeit zu gewährleisten, betreiben Cloud Services Anbieter meist zahlreiche Rechenzentren weltweit und ordnen diese verschiedenen Regionen und Verfügbarkeitszonen zu. AWS Kunden können derzeit auf 55 sogenannte Availability Zones (AZ) in 18 geographischen Regionen zugreifen, wobei die einzelnen Regionen jeweils aus mehreren Availability Zones bestehen. Jene Verfügbarkeitszonen werden als physisch getrennte Standorte definiert. Zu diesen isolierten Availability Zones gehört mindestens ein Rechenzentrum mit eigenständiger Stromversorgung, Kühlung und Netzwerkanbindung. Diese Struktur ermöglicht es Cloud Kunden, von Anfang an mitzubestimmen, wo Daten und Anwendungen gehostet werden. Somit können Sie mit redundant ausgelegten Infrastrukturen den Grundstein für hochverfügbare Services legen.
Compute, Databases und Storage
Mit AWS können Sie Hochverfügbarkeit für Ihre Cloud-Auslastung in verschiedenen Dimensionen erreichen, z,B.:
- Compute Cloud:Amazon EC2 (Elastic Compute Cloud) und andere Services, die Rechenressourcen bereitstellen, bieten Hochverfügbarkeitsfunktionen wie Lastausgleich, automatische Skalierung und Bereitstellung über Amazon Availability Zones an, die isolierte Teile eines Amazon-Rechenzentrums darstellen.
- SQL databases:Amazon RDS (Relational Database Service) bietet Optionen für die automatische Bereitstellung von Datenbanken mit einem Standby-Replikat in einer anderen AZ.
- Storage services:Amazon Storage Services, wie S3 (Simple Storage Service), EFS (Elastic File System) und EBS (Elastic Block Store), bieten integrierte Hochverfügbarkeitsoptionen. S3 und EFS speichern Daten automatisch in verschiedenen AZs, während EBS die Bereitstellung von Snapshots in verschiedenen AZs ermöglicht.
Aber auch alle anderen Aspekte Ihrer Infrastruktur lassen sich Ihren Wünschen gemäß hochverfügbar auslegen und somit an Ihre Anforderungen anpassen.
Der gewünschte Grad an Hochverfügbarkeit ist ausschlaggebend für die Maßnahmen, die Sie entlang des gesamten Lebenszyklus einer Anwendung treffen müssen, um die entsprechende Uptime zu gewährleisten.
Dabei sind ein paar Richtlinien zu befolgen:
- Konzipieren Sie das System so, dass es keinen Single Point of Failure (SPoF) gibt. Verwenden Sie automatische Überwachungs-, Fehlererkennungs- und Failover-Mechanismen sowohl für zustandslose als auch für zustandsabhängige Systemkomponenten.
- Single Points of Failure werden in der Regel mit einer N+1- oder 2N-Redundanzkonfiguration eliminiert, wobei N+1 durch Lastausgleich zwischen aktiv-aktiven Nodes und 2N durch ein Paar von Nodes in Aktiv-Standby-Konfiguration erreicht wird.
- AWS verfügt über mehrere Methoden, um High Availability durch beide Ansätze zu erreichen, z. B. durch einen skalierbaren, lastverteilten Cluster oder durch die Bereitstellung eines Aktiv-Standby-Paares.
- Bewerten und testen Sie die Systemverfügbarkeit nach den höchsten Standards.
- Bereiten Sie Arbeitsabläufe für manuelle Mechanismen vor, um auf den Ausfall zu reagieren, ihn abzuschwächen und ihn zu beheben.
Disaster Recovery
Sollte es trotz aller Vorkehrungen doch einmal zu einem Störungsfall kommen, ist es hilfreich, sich schon im Vorfeld einen Plan mit Maßnahmen zur Wiederaufnahme des Betriebs zu erarbeiten, einen sogenannten “Disaster Recovery Plan”. Dieser soll die Wiederherstellung der Daten oder wichtiger IT-Services nach einem Störungsfall sicherstellen.
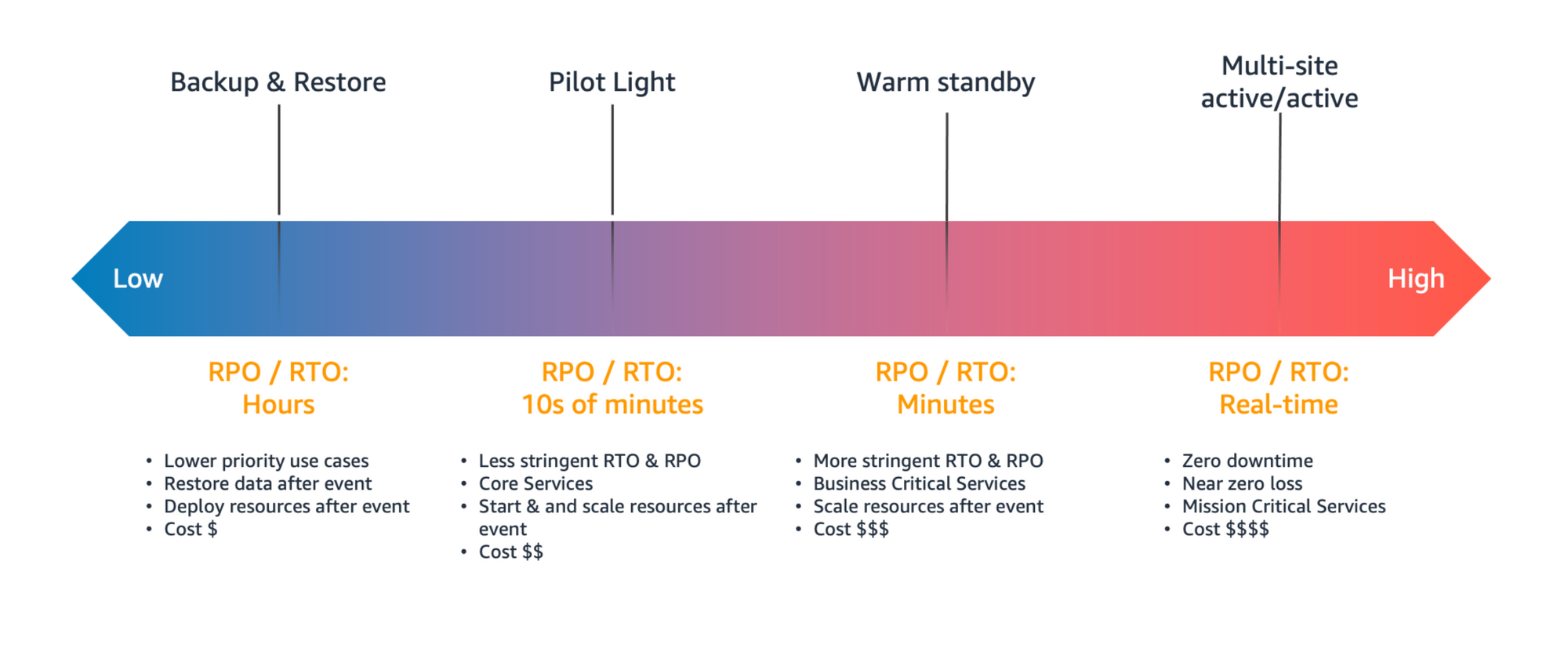
Die Notfallwiederherstellung kann auch als Leistung aus der Cloud in Form von Disaster-Recovery-as-a-Service (DRaaS) bezogen werden. AWS stellt Ihnen verschiedene Disaster-Recovery Strategien zur Verfügung, die grob in 4 Kategorien eingeteilt werden können und die von der kostengünstigen und wenig komplexen Erstellung von Sicherungen bis hin zu komplexeren Strategien mit mehreren aktiven Regionen reichen.
Scandiolife auf Instagram.
Hier zwitschert die Scandio auf Twitter.

